
AI Inventors 개발 Story
AI Inventors History#2-1 "Personalcolor AI 개발 - 이미지 크롤링(네이버/구글 이미지 크롤링)" 본문
AI Inventors History#2-1 "Personalcolor AI 개발 - 이미지 크롤링(네이버/구글 이미지 크롤링)"
ai.inventors 2020. 8. 14. 00:46안녕하세요 :)
AI Inventors 입니다.
이번 포스팅에서는 Personalcolor AI를 만들기 위해
어찌보면 가장 중요한 과정이었던 이미지 크롤링에 대해 공유해보고자 합니다.
※ PersonalcolorAI 서비스는
Backend는 Python으로, Frontend는 Bootstrap 기반의 HTML/CSS/JavaScript를 기반으로 작성하였으며,
금번 포스팅에서부터의 개발 Story는 기본적인 파이썬 내용을 알고 계시다는 가정하에 진행되는 내용이므로
파이썬 기초 내용에 대한 학습이 필요하시다면 타 유튜브 강의 등을 활용하시는 것을 권장드리겠습니다.
(추후 포스팅을 통해 파이썬 기초 내용도 포스팅할 예정입니다.)
1. 크롤링(Crawling) 이란?
웹 상에는 수많은 데이터들이 떠다니고 있습니다.
이 데이터들을 우리가 필요한 어플리케이션을 만들고, 가공하기 위해
날것의(Raw) 데이터를 긁어오는(수집하는) 과정이라고 생각하시면 될 것 같습니다.
2. 크롤링 방법?
저희는 웹 크롤링을 정적 웹 크롤링 / 동적 웹 크롤링 두 가지 방법으로 구분하여 생각하고 있습니다.
두 가지 Case에 따라, 사용해야 하는 테크닉이 다르기 때문입니다.
정적 웹은 서버에 미리 저장되어 있는 HTML/CSS 파일을 그대로 가져오는 방식이고,
동적 웹은 서버의 데이터들을 Script에 의해 한번 가공을 거친 후 가져오는 방식입니다.
(참고 : https://titus94.tistory.com/4)
일반적으로 주로 사용하는 검색엔진인 구글/네이버를 기준으로,
구글은 이미지 디스플레이 시 동적 웹 방식을 사용하며, 네이버의 경우 정적 웹 방식을 사용하고 있기 때문에
각자 다른 크롤링 방식을 사용하여 이미지를 긁어오시면 되겠습니다.
※ 구글/네이버 이미지 디스플레이 방식 비교
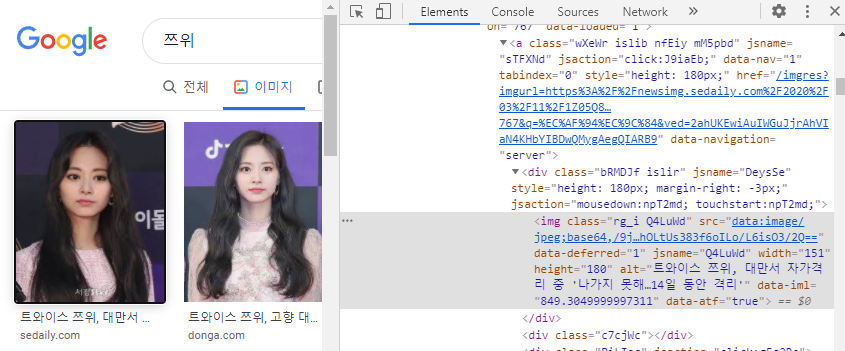
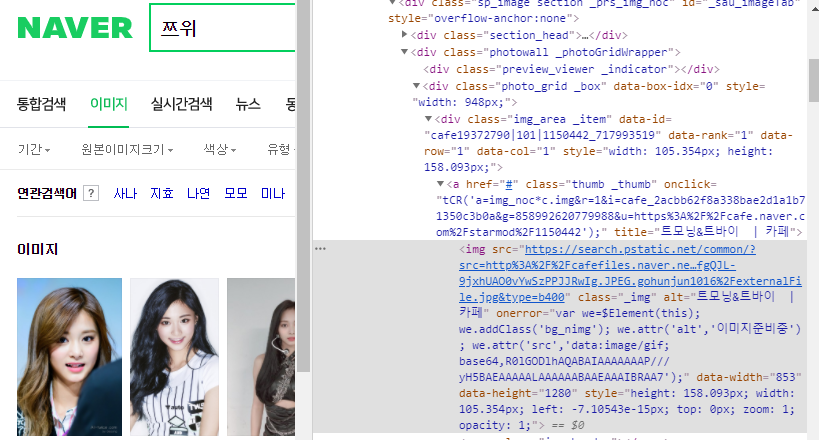
어떤 크롤링 방식을 사용할지 여부는
각 검색엔진에서 이미지를 검색 하신 후 F12키를 눌러서 개발자 도구를 여신 후 (Chrome 브라우저 기준)
HTML 소스를 보셔서 IMG Tag를 확인하셨을때,
위의 네이버 예시처럼 바로 IMG 태그 내 src에 http나 https URL이 확인 되신다면
정적 웹 크롤링 방식을 사용하시면 되고,
위의 구글 예시처럼 바로 URL이 확인되지 않고, 한번 가공된 소스가 확인되신다면 동적 웹 크롤링 방식을 사용하시면 되겠습니다.
3. 세부 크롤링 방식
저희는 기본적으로, BeautifulSoup 패키지를 이용한 웹 크롤링 방식을 사용하였지만,
Selenuim을 이용한 동적 웹 크롤링 방식과 BeautifulSoup pkg를 혼합하여 사용하였습니다.
위에서 설명드렸던 것처럼,
네이버에서는 이미지를 디스플레이하는 것 자체는 정적웹 방식을 사용하고 있기 때문에,
정적 웹 크롤링만 사용하셔도 이미지 데이터를 긁어오는 데는 전혀 문제가 되지 않습니다.
하지만, 대량의 이미지 데이터가 필요한 경우에 최대한 많은 이미지 데이터를 긁어와야 하는데,
네이버 웹 페이지에서는 한 스크롤 당 50개의 이미지 데이터만 디스플레이 해주고,
스크롤이 최 하위 포지션으로 내려갔을 때, 더보기 버튼이 활성화되면서 50개씩 더 보여주는 Script가 동작하고 있습니다.
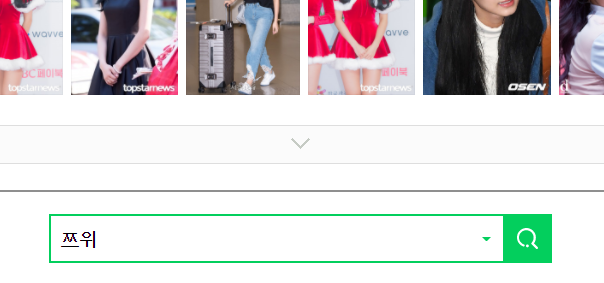
따라서, 단순히 Image Crawling 코드를 작성하셔서 이미지 데이터를 긁어오시면
50개씩 밖에 이미지 데이터를 들고올 수 없기 때문에,
대량의 데이터 수집이 불가능합니다.
이를 회피 하기 위해
저희는 Python의 Selenium PKG를 이용하여,
Chrome 브라우저를 제어한 채, 검색어를 입력한 후 스크롤을 최 하단으로 내린 상태에서
requests로 html 코드를 파싱해 올 수 있도록 코드를 작성하였습니다.
이 방식을 사용하면 한번에 최대 500개의 이미지 데이터를 저장해올 수 있습니다.
(물론, 이 500개라는 숫자 역시 많은 숫자는 아니기에, 여기에 약간의 트릭을 더 섞어 최대 5000장의 이미지 데이터를 가져올 수 있도록 하였습니다.)
from selenium import webdriver
import requests
from bs4 import BeautifulSoup
import urllib
from urllib import request
from urllib.request import urlopen
import os
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome('chromedriver',options=options)
for idx, search in enumerate(search_dict.keys()):
answer = list(search_dict.values())[idx]
os.makedirs(f'./images/{search}_{answer}')
url = f"https://search.naver.com/search.naver?where=image&sm=tab_jum&query={search}"
wd.get(url)
for i in range(800):
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
soup = BeautifulSoup(wd.page_source, 'html.parser')
tags = soup.select("img._img")
for i in range(len(tags)):
file_path = f'./images/{search}_{answer}/images' + str(i) + '.jpg'
urllib.request.urlretrieve(tags[i]["src"], file_path)
print(file_path)
일반 유저분들께서는 GPU환경이 아니실테니
Keras를 사용하시려면 주로 구글 Colaboratory에서 사용하실 것 같아,
구글 Colab 환경을 기준으로 설명드리고자 options의 일부 코드를 추가하였습니다.
구글 colab에서는 Ubuntu 서버 기반의 가상머신을 유저들에게 대여해주는 방식을 사용하고 있기에,
구글 colab이외의 브라우저 등의 어플리케이션을 가상머신 위에서 동작시킬 수 없습니다.
따라서, Selenuim을 사용하실 때, 브라우저를 띄우지 않고 사용할 수 있도록 코드를 추가해주셔야 합니다.
이외에는 기본적인 Selenuim, BeautifulSoup PKG 사용방식과 동일합니다.
빠른 데이터 전처리 과정을 위해,
Search Dictionary를 생성하여, 검색어에 들어가는 연예인 이름을 Key에 저장하고, 정답인 퍼스널컬러 라벨을 value에 작성하여 저장하였습니다.
이후, 이미지를 저장할 때 디렉토리에 Key_value 형태로 각 연예인별로 폴더를 만들어 그 하위에 이미지 데이터들을 저장하도록 하였습니다.
(ex) images/쯔위_가을웜딥/images1.jpg
앞서 말씀드렸던 것처럼,
네이버 기준으로 기본 BeautifulSoup 정적 웹 크롤링 방식만을 사용하면
한번에 50개의 이미지 데이터밖에 가져올 수 없기 때문에,
최대 500개의 이미지 데이터를 가져올 수 있도록, 아래의 Loop 구문을 추가하였습니다.
for i in range(800):
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
사실 800번까지 해도,
네이버에서 제공하는 최대 횟수가 10번이기 때문에 큰 의미는 없습니다만
처음에는 최대 횟수를 알지 못해서 무작정 큰 숫자를 넣어보자는 생각에 800번으로 작성했었습니다.
금번 포스팅에서는
퍼스널컬러AI를 개발하는데 기본 토대가 된 백데이터 수집 과정(이미지 크롤링) 을 소개드렸습니다.
감사합니다.
Have a Nice day~!
AI Inventors.
'IT 개발 프로젝트 > Personalcolor AI 개발' 카테고리의 다른 글
| AI Inventors History#2-5 "Personalcolor AI 개발 - Nginx 연동" (1) | 2020.09.01 |
|---|---|
| AI Inventors History#2-4 "Personalcolor AI 개발 - Flask Framework 구현" (1) | 2020.08.27 |
| AI Inventors History#2-3 "Personalcolor AI 개발 - AI Train Data 생성" (0) | 2020.08.25 |
| AI Inventors History#2-2 "Personalcolor AI 개발 - 얼굴인식과 얼굴 피부 추출" (0) | 2020.08.14 |
| AI Inventors History#2-0 "Personalcolor AI 개발" (0) | 2020.08.12 |

