
AI Inventors 개발 Story
AI Inventors History#2-3 "Personalcolor AI 개발 - AI Train Data 생성" 본문
AI Inventors History#2-3 "Personalcolor AI 개발 - AI Train Data 생성"
ai.inventors 2020. 8. 25. 01:56안녕하세요
AI Inventors 입니다 :)
오늘은 Personalcolor AI 모델을 만들기 위한 전 단계 중
AI Train Data 생성 부분을 공유드리고자 합니다.
오늘 공유드릴 주요 포인트를 세 가지로 구분하자면,
1. 이미지파일에서 Key Feature들 추출 후 Feature Dataframe 생성
2. File 입출력 오류 예외처리
3. Standardization
이 될 것 같습니다.
1. 이미지파일에서 Key Feature들 추출 후 Feature Dataframe 생성
우선, 저번 포스팅에서 크롤링을 통해 저장했던 이미지들을 불러오겠습니다.
file_paths = os.listdir('/root/images')os.listdir이라는 함수를 통해, images내의 폴더들을 긁어옵니다.
참고로, os 모듈의 listdir 함수는 해당 디렉토리 내의 파일들을 전부 긁어와서 list 자료형으로 리턴해주는 함수 입니다.
(https://wikidocs.net/39)
listdir로 디렉토리를 긁어오면, 아래와 같은 리스트를 리턴받을 수 있는데요
['EXO카이_겨울쿨_딥', 'ITZY리아_여름쿨_라이트', 'ITZY류진_가을웜_딥', 'ITZY유나_가을웜_뮤트',
'강민희_여름쿨_라이트', '강혜원_가을웜_뮤트', '강호동_봄웜_라이트', '구구단세정_가을웜_딥' ...]저희가 크롤링을 해올 때, 이미지파일들을 저장하면서
라벨Data로 사용할 "계절타입, 세부톤"을 기록해놓기 위해
파일을 "/images/연예인명_계절타입_세부톤/images_01.jpg" 형태로 저장했기 때문에,
파일을 긁어올 때, images 내의 연예인별 폴더를 전부 긁어오고,
연예인 별 폴더 내의 이미지 파일들을 또 한번 전부 긁어오는 이중 작업을 해줘야 합니다.
물론, 더 간편한 방법이 있을 수 있으나 제 아이디어의 한계로 ㅠㅜ
하여, 아래와 같은 방식으로 이중으로 작업을 해야 합니다!
for idx, filePath in enumerate(file_paths):
train_imagePaths = list(paths.list_images(os.path.join('/root/images', filePath)))
for index, imagePath in enumerate(train_imagePaths):
이 중, enumerate함수는
for 반복문을 돌때, list 명 앞에 enumerate(list명) 형태로 적어주게 되면,
list에서 index와 value값을 동시에 뽑아올 수 있게 됩니다.
제가 작성한 코드에서는 큰 의미가 있는 기능은 아니지만,
대량의 Data를 사용하여 Feature들을 가공하고 추출하면서
어디까지 진행됐나 진척도를 확인할 용도로 사용했었습니다.
2. File 입출력 오류 예외처리
저희 PersonalcolorAI에서는 이미지들을 가져와서, 얼굴과 눈을 인식하고, 그 안에서 피부톤을 추출해내는 작업을 합니다.
따라서, 얼굴과 눈이 인식되지 않는다면, 피부톤을 정상적으로 인식할 수가 없게 됩니다.
헌데, 웹 상에서 크롤링으로 가져온 이미지 데이터들 중에는
얼굴이 인식되지 않는 데이터, 눈이 인식되지 않는 데이터, 눈을 감은 데이터 등등 아주 많은 오류들이 발생하게 됩니다.
이런 이미지들은 피부톤을 추출할 수도 없고, Feature들을 뽑아낼 수도 없기 때문에,
머신러닝/딥러닝에 넣기 전에 이미지 제거를 해줘야 합니다.
Python 기본 문법을 참조하시면, try/except 구문을 찾으실 수 있습니다.
(https://wikidocs.net/30)
try:
~~~
except:
xxxxx의 형태로 사용합니다.
try문 하단에 내가 실제로 사용하고자 하는 기능을 집어넣고,
except 문 하단에, 오류가 발생했을 때 어떻게 처리할 것인지를 집어넣으면 예외처리 구문이 동작하게 됩니다.
아래 내용은 for문 내의 내용이라고 보시면 되는데요
try :
feat_1, feat_2, feat_3, feat_4, feat_5, feat_6 = pcolor_analysis(imagePath)
value_data.append([feat_1, feat_2, feat_3, feat_4, feat_5, feat_6])
name, season, detail = filePath.split("_")
result_list.append(result_dict[season + detail])
except :
os.remove(imagePath)
pcolor_analysis가 얼굴인식/눈 인식/피부추출 기능이 들어가있는 함수 부분이라고 보시면 되겠습니다.
기본 동작은 pcolor_analysis에 image 경로를 집어넣게 되면, 피부 부분을 추출하고, 그 속에서 Key Feature들을 뽑아오는 동작이라고 보시면 됩니다.
물론, 실제로 뽑아오는 Feature들은 6개 이상이지만, 포스팅 편의를 위해....
앞서 말씀드렸다 싶이,
얼굴/눈이 정상적으로 인식되지 않는 이미지 파일들은 Data로써의 효용가치가 없기때문에,
과감하게 삭제를 해줄 예정입니다.
따라서, 오류의 예외처리 부분인 except 구문의 하위에
os.remove함수를 써서, 해당 경로의 파일을 삭제하도록 지시하였습니다.
또한, 실제로 코드를 작성할 때는
사람이 2명이상 들어있는 경우에, AI학습 데이터가 어느 사람을 실제 Feature로 추출해올 지 모르기 때문에,
한 이미지 내에 얼굴이 2개 이상 인식될 경우 역시 파일을 삭제하도록 코드를 작성하였습니다.
그리고, 위에 보시면 result_dict에 label data를 넣어서 숫자값으로 받아오는 코드가 있습니다.
머신러닝/딥러닝에 넣을때는 이 한글 Label Data를 그대로 넣어서 사용하기보다는
one-hot encoding 형태로 바꿔서 넣어주기 위해, 숫자로 변환하여 주었습니다.
물론, 한글 Label을 그대로 one-hot encoding 쳐도 문제는 없으나,
추후, Data 처리 시 편의를 위해....
result_dict = { '봄웜라이트': 0,
'봄웜브라이트': 1,
'여름쿨라이트': 2,
'여름쿨뮤트': 3,
'가을웜뮤트': 4,
'가을웜딥': 5,
'겨울쿨브라이트': 6,
'겨울쿨딥': 7}
3. Standardization
우선 의문이 드실 두 가지를 정리하고 넘어가겠습니다.
1) Scaling은 왜 해야하는가?
2) Scaling방식(standardization / normalization) 별 차이는 무엇인가?
1) Scaling은 왜 해야하는가?
Scaling에 대한 다양한 정의와 의미가 있겠지만,
저는 딱 이렇게 생각합니다.
"Feature별로 값의 범위가 다르기 때문에, 그 Range를 일원화 시켜줘서
Feature들 간의 중요도를 일원화 시키는 것" 이라고 생각합니다.
예를 들어, 특정 회사의 제품 판매량을 예측하는 머신러닝 알고리즘을 만든다고 할 때,
영향받는 변수로 온도/습도/유동인구 등을 Feature로 넣는다면,
당연히 온도와 습도, 유동인구는 Range가 다르겠죠?
온도가 20~30도 사이에서 변하고,
유동인구가 2만명 ~ 5만명 사이에서 값을 가진다고 할 때,
이 경우, 온도가 1변하는 것과 유동인구가 1 변하는 것은 당연히 임팩트가 다를겁니다.
따라서, 각각의 Feature별로 영향도/중요도를 유사하게 맞추기 위해 Scaling 작업이 필요하다고 생각합니다.
물론, Feature별로 어느 지표는 더 중요하고, 어느 지표는 덜 중요할 수 있습니다.
이 경우, Standardization/Normalization 등의 방법을 통해, 일괄 Scaling을 적용하고,
Feature별로 가중치를 둬서 Weight를 곱해가는 방식으로 중요도를 Tuning할 수 있습니다.
2) Scaling방식(standardization / normalization) 별 차이는 무엇인가?
Standardization은 일명 Z-score Scaling이라고도 하고,
normalization은 Min Max Scaling 이라고도 합니다.
Standardization은 아래 공식에서 볼 수 있듯이, Data값에서 평균을 빼고, 표준편차 값으로 나눠주면 됩니다.
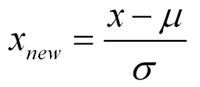
Standardization을 적용하면, 평균이 0, 표준편차가 1인 값들로 scaling이 적용되게 됩니다.
Normalizaiton은 아래 공식처럼, Data에서 Data 중 최소값을 빼고, Data 중 최대값 에서 최소값을 뺀 값으로 나눠주면 됩니다.
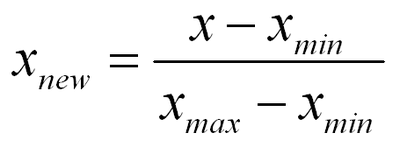
이 경우, Normalization을 적용하면 Data의 Range가 최대값 1, 최소값 0인 Data들로 Scaling이 적용되게 됩니다.
Normalization과 Standardization의 차이는 아래 링크의 블로그에 너무 잘 정리가 되어있어
참조할만한 자료로 가져왔습니다.
(https://skyil.tistory.com/50)
링크에도 나와있듯이,
Standardization은 Z-score값을 계산해서, Z-score의 절대 값이 2 이상인 Data들을 삭제해주는 작업을 함께 진행하곤 합니다.
이렇게 하면, outlier(이상치) 값들을 제거해버릴 수 있기 때문에,
Standardization은 상대적으로 Normalization에 비해, 이상치가 많은 데이터들에서 성능이 좋은 편입니다.
사족이 길었는데요.
저희가 웹에서 크롤링해온 데이터들은 사실, 이상치들이 워어어낙 많기 때문에, Z-score를 적용한 Standardization을 사용하여 Scaling작업을 진행하였습니다.
feat_1_std = std([temp[0] for temp in value_data])
feat_1_mean = mean([temp[0] for temp in value_data])
feat_2_std = std([temp[1] for temp in value_data])
feat_2_mean = mean([temp[1] for temp in value_data])
feat_3_std = std([temp[2] for temp in value_data])
feat_3_mean = mean([temp[2] for temp in value_data])
feat_4_std = std([temp[3] for temp in value_data])
feat_4_mean = mean([temp[3] for temp in value_data])
feat_5_std = std([temp[4] for temp in value_data])
feat_5_mean = mean([temp[4] for temp in value_data])
feat_6_std = std([temp[5] for temp in value_data])
feat_6_mean = mean([temp[5] for temp in value_data])
std_list = [feat_1_std, feat_2_std, feat_3_std, feat_4_std, feat_5_std]
mean_list = [feat_1_mean, feat_2_mean, feat_3_mean, feat_4_mean, feat_5_mean]
for temp in value_data:
for i in range(len(temp)):
temp[i] = (temp[i] - mean_list[i]) / std_list[i]
우선, 각 Feature별로 표준편차 값(std)과 평균 값(mean)을 뽑아줍니다.
그리고 이전에 저장해놨던 value_data에서 row별로 데이터를 들고와서,
row내의 각 feature별로 평균값을 빼주고, 표준편차값으로 나눠주는 Standardization Scaling을 적용해줍니다.
이 뒤에, 코드를 더 작성해서, temp값의 절대값이 2가 넘으면,
해당 row는 버리도록 코드를 z-score scaling을 추가 적용하였습니다.
감사합니다.
Have a Nice day~!
AI Inventors.
'IT 개발 프로젝트 > Personalcolor AI 개발' 카테고리의 다른 글
| AI Inventors History#2-5 "Personalcolor AI 개발 - Nginx 연동" (1) | 2020.09.01 |
|---|---|
| AI Inventors History#2-4 "Personalcolor AI 개발 - Flask Framework 구현" (1) | 2020.08.27 |
| AI Inventors History#2-2 "Personalcolor AI 개발 - 얼굴인식과 얼굴 피부 추출" (0) | 2020.08.14 |
| AI Inventors History#2-1 "Personalcolor AI 개발 - 이미지 크롤링(네이버/구글 이미지 크롤링)" (0) | 2020.08.14 |
| AI Inventors History#2-0 "Personalcolor AI 개발" (0) | 2020.08.12 |

